I am now looking to create spatial clusters from the source estimate data with SurfClust. I am specifically wondering if input dataset can be the output from this tutorial (a .niml.dset file) or if I will need to convert it to another form for use.
*.niml.dset files can be used with clustering. They contain information at nodes, values that can be thresholded, for example. You also need the information of the topology/relatedness of mesh nodes, which are contained in *.gii files or in groups of GII files, the latter of which can be loaded in with *.spec files.
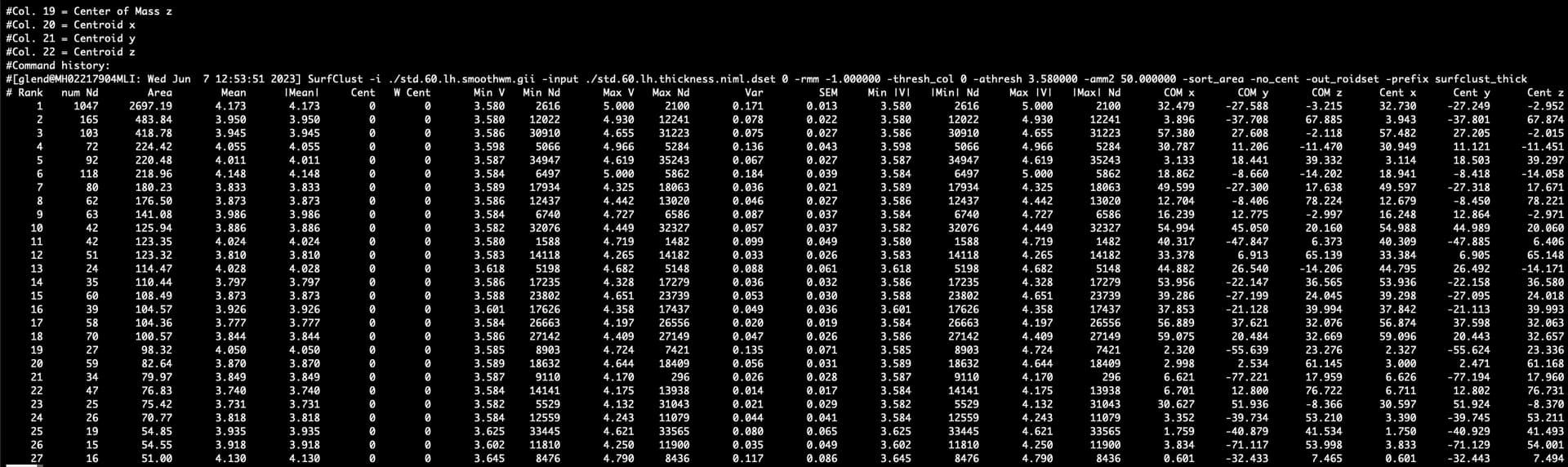
… where the following are input: a dset (./std.60.lh.thickness.niml.dset, which is the dset that is thresholded (here at 3.58) + clusterized (here with NN=1, from ‘-rmm -1’)), which is overlaid on the “underlay” data set (std.60.lh.smoothwm.gii) that contains the mesh information, and the other options are described in the help file. Note how with the -input .. dset, you also specify which subvolume is used for clusterizing (even if there is only a single volume there, so you select the 0-th vol):
-input inData.dset dcol_index: The input dataset
and the index of the
datacolumn to use
(index 0 for 1st column).
Values of 0 indicate
inactive nodes.
If your -input .. dset had more than one value per node (like a time series, for example), you could select a different subvolume from it for clusterizing.
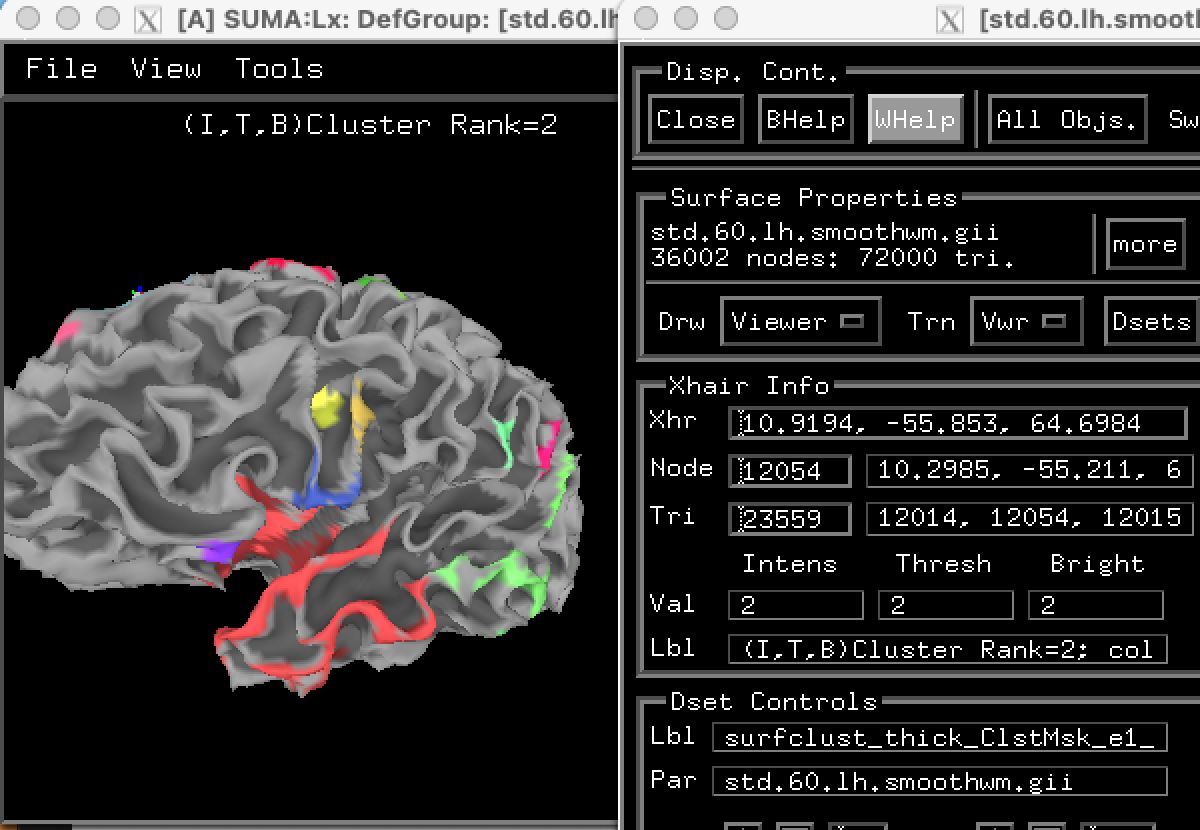
I am wondering if there is a way to see which nodes belong to which clusters when you use the -out_fulllist parameter. I want to preserve the row-to-node correspondence since I'll be comparing across multiple datasets, but want to know if I can tell nodes apart by their specific cluster. I thought the -out_roidset parameter does something like this, but that doesn't seem to be the case...
Nodes are recorded for each cluster in the out_roidset dataset - nodes in Cluster 1 get a value of 1, cluster 2 get a value of 2 at every node and so on ....
Add the -out_roidset and the -prefix option to Paul's example command to name the output.
You can see all nodes in any or some of the clusters with 3dmaskdump. The mrange is an option to limit to only a particular range of cluster values in the mask (here limiting to just cluster 2). The output shows i j k indices for the mask values, but only the i index is useful for surface mesh nodes.
The
National Institute of Mental Health (NIMH) is part of the National Institutes of
Health (NIH), a component of the U.S. Department of Health and Human
Services.