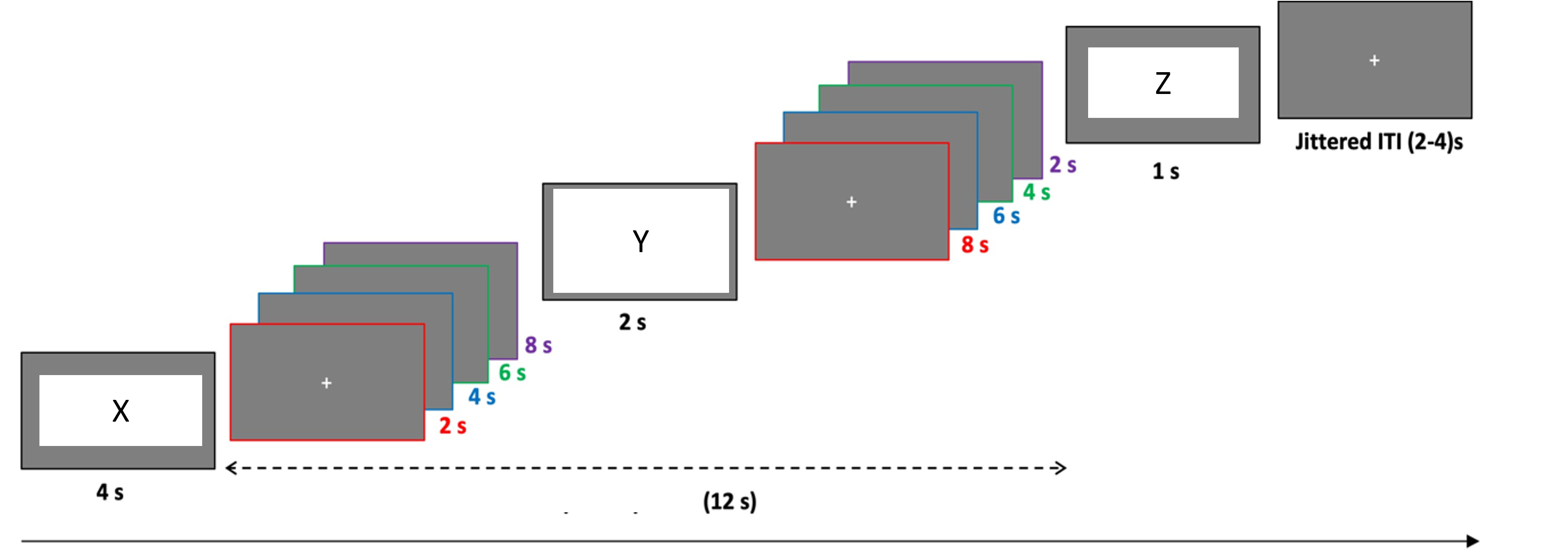
I have the following experimental design that I would like to analyze with an FIR approach with AFNI. My goal would be estimate HRF between X-Y and Y-Z events for two separate conditions (so X1-Y1,Y1-Z1, X2-Y2,Y2-Z2). I've used AFNI for group-level analysis before, but this would be first time doing FIR and first-level in AFNI.
So a given trial might be: X1-Y1 - 4s interval; Y1-Z1 - 6s interval.
There are a number of challenges that I'd like to seek advice with in how to best incorporate AFNI:
Unfortunately there is variable time interval both before and after Y, which gives me the impression that I will need to build a custom design matrix for each participants each run. Is there anything I should be aware of when running 3dDeconvolve? I realize that due to my experimental design the estimates for the later time points will be noisier than for the earlier ones because there is less samples for those.
To complicate matters further, not all participants completed the same amount of runs so this variability should be incorporated in the second-level estimates. I believe this means that I will need to run 3dLMER on the second level correct?
What is the correct procedure to compare my two conditions FIR time courses? Can one do non-parametric cluster correction for each beta of each TR.. and then somehow correct for multiple comparisons additionally due to the multiple TRs?
there is variable time interval both before and after Y, which gives me the impression that I will need to build a custom design matrix for each participants each run. Is there anything I should be aware of when running 3dDeconvolve?
To clarify, are you trying to capture the BOLD responses for the four intervals of X1-Y1,Y1-Z1, X2-Y2, and Y2-Z2? How many trials do you have for each of those four intervals? Does the duration vary across trials for each specific interval?
To complicate matters further, not all participants completed the same amount of runs so this variability should be incorporated in the second-level estimates. I believe this means that I will need to run 3dLMER on the second level correct?
If you want to estimate the HRF at the individual level, 3dMSS would be a suitable option as discussed here.
What is the correct procedure to compare my two conditions FIR time courses? Can one do non-parametric cluster correction for each beta of each TR.. and then somehow correct for multiple comparisons additionally due to the multiple TRs?
It would be better to treat each HRF as a whole continuous curve rather than a number of discrete data points. See the same 3dMSS discussion mentioned above.
Correct! One run contains 32 trials, evenly distributed along those intervals and the two conditions, meaning per run there would be 8 trials with either [XY:2s,YZ:8s], [XY:4s,YZ:6s], [XY:6s,YZ:4s], [XY:8s,YZ:2s], this is split into two due to the two conditions, giving us 4 trials per run per condition per interval. I have on average 3 runs per participant completed successfully.
This is the only variation related to timing (+also there is a 2-4s jitter at the end of each trial). So in terms of the condition specific XY interval per run we have 16 trials that cover the the first 2s, 12 trials that cover the first 4s, 8 trials that cover the first 8s and only 4 trials where we can see the full 8s. On average I have 48 trials per participant per condition.
Yes, its a within subject design so I would like to compare the HDR time course between the two conditions (-> (3) HDR contrast between two task conditions). I've read about these TENT functions, however given that I have these variable interval durations I don't think I can easily take advantage of them. What would you suggest?
If I were to follow the tutorial option 3 would look like?
To clarify, I have the following follow-up questions:
You mentioned two conditions, and for each condition, there are four different intervals, namely [XY: 2s, YZ: 8s], [XY: 4s, YZ: 6s], [XY: 6s, YZ: 4s], and [XY: 8s, YZ: 2s]. Is this correct?
Are you looking to distinguish between these four intervals for each condition? If so, would that mean estimating a total of eight HRFs?
Considering each interval lasts for 10 seconds, are you planning to estimate the HRF for such extended intervals?
Ideally, I would be able to estimate an overall 8s long HDR for XY_1, YZ_1, XY_2, YZ_2 (where the _* refers to the condition). Thus reducing the problem to estimating 4 HRFs instead of 8. I realize that the experiment could have been designed differently to support this approach better, such as having fixed 8s intervala between each stimuli/event.
In light of the previous answer the goal would be to estimate two separate 8s interval, or 10s if we include the duration of Y, as you mention. I think the cleanest way would be to estimate the 8s inter-event intervals that can maximally take place between X and Y or Y and Z.
I only have experience in estimating HDRs with event-related datasets. It would be intriguing to observe how this translates to a block-type dataset like yours. Use TENTzero in 3dDeconvolve if multicollinearity is a concern.
Apologies, I believe I might have created the impression of block design when grouping the trials into bins to count them:
Condition
XY interval
YZ interval
Number of trials
1
2s
8s
4
1
4s
6s
4
1
6s
4s
4
1
8s
2s
4
2
2s
8s
4
2
4s
6s
4
2
6s
4s
4
2
8s
2s
4
but in actuality the experiment proceeded in an event-based fashion, by uniform random sampling from these trial types, so a run might look like:
TrialNum
Condition
XY interval
YZ interval
Jitter
1
1
2s
8s
rand(2,4)
2
2
6s
4s
rand(2,4)
3
1
8s
2s
rand(2,4)
4
1
4s
6s
rand(2,4)
…
This leads to my main struggle with 3dDeconvolve's TENT(x,y,z). If I understand correctly this assumes a fixed interval between Event1 and Event2 throughout the run, whereas in my case its variable. Splitting the data is also not an option because, then I wouldn't be taking advantage of the overlapping signal between variable intervals:
for example the first two seconds of the condition-specific HDR should be estimated using all 16 trials of a given run; the [2,4] interval should use all 12 trials available, the [4,6] interval should use all 8 trials; the [6,8] interval should use all 4 trials.
I'm still grappling with understanding the structure of your experimental design as it remains unclear to me. Let me attempt to outline my confusions.
Do both X and Y have two levels? Is Y dependent on X?
Are X and Y considered as instantaneous events or intervals with varying durations?
Based on your description, it appears that you have four distinct events (X1, X2, Y1, and Y2) for which you'd like to capture their HDRs. However, your emphasis on these intervals has left me a bit confused.
Yes yes, Y is dependent of X. So X1 is only paired with Y1 and relatedly Y1 is only paired with Z1. Similarly X2 is only paired with Y2, Y2 with Z2. So there are these two kinds of event "tuples". X1 will never be paired with Y2.
When referring to X and Y I'm thinking of instantaneous events - the event of the stimulus appearing on the screen and staying on the screen for a fixed amount of time. When referring to XY, or YZ I'm referring to the inter-stimulus-interval between them, so when I wrote XY I was referring to the variable time interval between the X and Y event. This can be either XY_1 or XY_2 depending on the condition.
I appreciate your time in trying to understand the design! Apologies if I wasn't clear before.
Yes, in hindsight that probably would have been a better way to phrase it. Indeed I interested in the post-stimulus HDR of X1, X2, Y1, and Y2. The reason I was frequently using the "interval" term is to highlight that I think because the time taking place between X and Y varies from trial to trial, it makes it seem tricky to apply TENT functions as they're typically used.
X1 is only paired with Y1, and correspondingly, Y1 is only paired with Z1. Similarly, X2 is only paired with Y2, and Y2 is only paired with Z2.
This suggests six event types: X1, X2, Y1, Y2, Z1, and Z2. Does it mean you're disregarding Z1 and Z2 in effect estimation?
The reason I frequently used the term "interval" is to emphasize that, due to the varying time between X and Y in each trial, applying TENT functions, as they are conventionally used, might pose challenges.
These intervals are crucial for disentangling the events in effect estimation. However, from a model specification perspective, they are irrelevant. One aspect to determine is the duration of the HDR you'd like to cover. For example, select a duration around 12 - 16 seconds. The three parameters, b, c, and n, in the formula of TENT(b,c,n) in 3dDeconvolve specify the beginning, end, and the number of linear splines. If you wish to cover 16 seconds of HDR duration with a TR length of 2 seconds, you might consider adopting TENT(2,16,8) with the following assumptions:
(1) No response is assumed at stimulus onset (0 s) and at the end (18 s).
(2) The HDR is estimated with 8 TRs (spline knots) covering the period from 2 to 16 s.
Indeed, post-"Z" interval is very short (Jittered 2-4s) and is not of primary interest in terms of HDR profile, but if I understand correctly this could be "added" to the overall HDR profile estimate as "extra 3s" (1s duration of Z plus 2s post stimulus jitter)?
This is very puzzling to me :) The TENT(2,16,8) will produce 8 spline knots, I guess one would estimate them separately for each condition. What I don't understand is how we can "ignore" that the Y event is happening at different times within that 2-16s interval? Will the TENT output give me the ability to interpret the first 4 spline knots as "pure" pre-Y signal?
post-"Z" interval is very short (Jittered 2-4s) and is not of primary interest in terms of HDR profile, but if I understand correctly this could be "added" to the overall HDR profile estimate as "extra 3s" (1s duration of Z plus 2s post stimulus jitter)?
A good model should aim to depict not only what the analyst is interested in but also how the data are generated. If the Z events are believed to trigger a neuronal response, it would be sensible to consider including those trials in the model. Again, it's these events — not the intervals before the next trial — that are associated with the BOLD response.
The TENT(2,16,8) will produce 8 spline knots, I guess one would estimate them separately for each condition. What I don't understand is how we can "ignore" that the Y event is happening at different times within that 2-16s interval? Will the TENT output give me the ability to interpret the first 4 spline knots as "pure" pre-Y signal?
The data from the scanner is conceptualized as a superimposition of BOLD responses to the six events (or mathematically speaking, the convolution of the HRF with stimulus events), alongside various 'noise' components. Assuming each HDR lasts for 16 seconds, we use TENT(2,16,8) to effectively capture the BOLD response to the six event types: X1, Y1, Z1, X2, Y2, and Z2. The regression model is designed to decompose the data, ideally revealing the individual HDRs associated with those six event types. Ultimately, the estimates at all 8 knots for each event type (not 4) provide an HDR profile for each event type.
Right, following that logic, one should include the first event as well as the last (the events are visual, text and images), resulting in a 4s (X_duration)+12s (ISI)+1s (Z_duration)+2s (min jitter) resulting in 19s which could be rounded up to 20? Producing TENT(0,20,11) for the most complete view of the trial?
Thank you, let me see if I understand correctly by outlining my analysis plan:
If X1-Y1-Z1 and X2-Y2-Z2 are tied together as two distinct conditions, employing something like TENT(0,20,11) does seem appropriate. One assumption here is that the BOLD response remains consistent across trials, irrespective of the randomization within those intervals.
Hence, from a modeling standpoint, this does align with a block design. It would be intriguing to see how the HDR estimation approach performs in such a scenario.
Yes yes - very illuminating! I'm extremely grateful for you time! Thank you.
The
National Institute of Mental Health (NIMH) is part of the National Institutes of
Health (NIH), a component of the U.S. Department of Health and Human
Services.