I have a question regarding using AFNI to analyze fMRI data. In my study, each participant views three different types of food images (representing three conditions: bundle, scale, single) and provides a preference rating for each food item. Once the participant responds, the trial ends, so the duration is essentially the participant’s reaction time, unless they take more than 4 seconds to respond.
If I only want to compare the activation differences across the three conditions, is it appropriate to use stim_times_AM1? I noticed that the timing files in AFNI generally don’t include duration information, which differs from FSL’s event files. In FSL, the event files have onset time in the first column, duration in the second, and weight in the third. However, in AFNI, duration time seems to be absent from the timing files. How can I incorporate the duration information for each trial into the model? Should I specify it in the dmUBLOCK() parameter? Additionally, based on my study design, is it reasonable to use dmUBLOCK()? I also saw recommendations for using dmUBLOCK(-). How should I decide which one to choose?
Additionally, if I want to include the participants’ preference ratings for each item in the model, should I switch to using stim_times_AM2? In that case, should the timing file (.1D) have two columns of weights: one with all values set to 1 (to capture activation differences across conditions) and the second with the mean-centered preference scores?
Below is my code, which only compares brain activation across different conditions. I really appreciate any help!
A complete event, with an onset, multiple amplitude modulators and a duration is specified with the format: ONSET*AMP_1*AMP_2:DURATION, as in 15.3*1.4*-0.8:2.1.
In the case of only duration modulation (e.g. 15.3:2.1, for an event at time 15.3 of duration 2.1 seconds), one would use -stim_times_AM1 (as you are). In this case, if you were to use both an amplitude modulator (preference rating, like 1.4) and a duration (like 2.1), an event might look like 15.3*1.4:2.1 .
With any amplitude modulator, one would usually use -stim_times_AM2. This would apply whether there are attached durations or not. It gives separate regressors/betas for the mean response and the modulation response.
While 3dDeconvolve can read FSL-formatted timing files, afni_proc.py will not (though they could be converted via timing_tool.py -fsl_timing_files. See timing_tool.py -help output for details or an example.
For your questions...
Using stim_times_AM1 is indeed appropriate, but basically only when events have only durations attached.
Using dmUBLOCK(-) works well when the mean duration is not close to either 0 or 15s. The parameter to dmUBLOCK affects only the scaling of the regressors/betas. So it does not affect single subject statistics, but it can affect group statistics if the mean duration varies across subjects. In such as case, it is good to use something like dmUBLOCK(-4.2) if the mean response time across all subjects is 4.2 s. This allows the betas to be appropriately compared across subjects and groups.
See : dmBLOCK options for a discussion about dmBLOCK/dmUBLOCK.
Hi Rick, I have a quick follow-up question. Below are a timing file of one subject: each onset time for a stimulus image is listed before the colon, with the duration following it. Since I have 5 runs, I’ve organized each line as one run. Would AFNI recognize this format as 5 separate runs?
Given that the trial durations vary only slightly (about one TR or less), it may not be worth modeling this variability in detail. Instead, you might achieve greater sensitivity in detecting the hemodynamic response by using the TENTzero basis function option, which allows for flexible response morphology. You could consider comparing both methods to evaluate detection sensitivity.
Indeed, 3dDeconvolve would interpret timing information across those five rows as originating from separate runs.
Thank you very much for your response! You mentioned that because the reaction times for each trial in my study are very small and have low variance, it is advisable to use TENTzero instead of dmUBLOCK(-).
In my script, since all participants need to respond within 4 seconds for each trial, meaning the maximum reaction time for each trial is 4 seconds, should I replace dmUBLOCK(-) with TENTzero(0, 4)? Additionally, do I need to make any modifications to the timing files?
Consider using TENTzero(0,16,9) to model a 16-second duration for the hemodynamic response, assuming a TR of 2 seconds. For the stimulus timing files, provide only the trial onset times without including duration values.
I truly appreciate your detailed response and guidance. I will proceed to analyze the data using both methods (dmUBLOCK(-) vs. TENTzero) to compare the results and see what differences emerge.
To assess the evidence for the BOLD response of a single condition (e.g., bundle) when using TENTzero(0,16,9), use the following specification in 3dDeconvolve:
-gltsym 'SYM: +bundle[[0..6]]'
To compare two conditions (e.g., bundle and scale), use:
-gltsym 'SYM: +bundle[[0..6]] -scale[[0..6]]'
You can also extract the 7 betas associated with TENTzero(0,16,9) for each condition from the 3dDeconvolve output and visually assess the profile of the estimated hemodynamic response using the Graph button in the AFNI GUI.
Thank you very much for your detailed guidance! I have modified my 3dDeconvolve code according to your suggestions, and I have a few additional questions.
I am aiming to compare activation differences across three conditions (similar to FSL event files where the first column is onset time, the second column is duration, and the third column has a weight of 1). I also want to include an amplitude modulator representing participants’ preference ratings for the stimulus images (similar to FSL event files where the third column represents the preference score). Here are my thoughts on each scenario:
Comparing Condition Activation Differences Only: If I only want to compare the activations across different conditions without including the preference score as an amplitude modulator, and I believe that modeling each trial’s duration time is unnecessary, then my timing .1D files for each condition would only include the onset times, with each run as a separate line. In this case, my script should follow the code I provided above, using -stim_times_AM1 , correct?
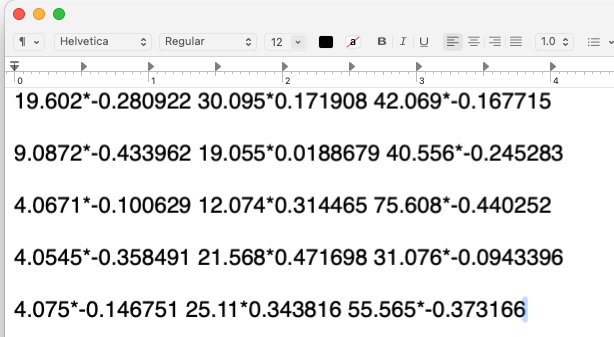
Including Preference Score as an Amplitude Modulator: If I want to include the participants’ preference scores as an amplitude modulator, I assume I should switch to -stim_times_AM2, and the timing .1D file for each condition would include the mean-centered preference scores. Would the setup look like the example in the image below? (To simplify, I only included the first 3 trials from each run.)
If this approach is appropriate, I have some further questions about the details:
Separate Betas for Mean Activation and Modulation: When using -stim_times_AM2, will I receive separate betas for the mean activation and for the modulation activation? If so, will the beta for the mean activation in this case be the same as the beta from the first scenario (where preference scores are not included)? If they differ, which one should I rely on?
Mean-Centering Preference Scores Within Each Run: When using preference scores as an amplitude modulator, should I mean-center them within each run and for each subject? If mean-centering is required, this raises another potential concern: if the scores are mean-centered, then lower preferences will be negative, higher preferences will be positive, and scores near the mean will be zero. As I understand it, AFNI treats periods outside of experimental trials (such as inter-trial intervals without any stimulus or response) as baseline, assigning a value of zero. In this case, would zero values for baseline (non-stimulus trials) be conflated with zero values from mean-centered preference scores? How can I adjust for this potential confusion?
Orthogonalization: If I use -stim_times_AM2, each condition will have two regressors in the model—one representing activation without considering preference scores and the other considering preference scores as an amplitude modulator. Should I set AFNI to perform orthogonalization (i.e., assigning any shared variance to the first entered regressor), or is orthogonalization unnecessary if I have already mean-centered the preference scores?
Clarification on TENTzero(0,16,9) Parameters and -gltsym Specification: You suggested using TENTzero(0,16,9) with -gltsym 'SYM: +bundle[[0..6]]'. Is the choice of 16 seconds an empirical standard? For the number 9, I assume it comes from dividing 16 by my TR (2s) and then adding 1. Regarding [[0..6]] and the 7 beta values you mentioned, I understand that it represents 7 values from 0 to 6, but I am not entirely sure why it results in 7 beta coefficients. My understanding was that each condition would yield a single coefficient (beta value). Could you clarify this?
I really appreciate your advice and apologize if some of these questions seem basic—this is my first time using AFNI to analyze fmriprep outputs, and I want to ensure I understand the process correctly. Thank you again for your time and help; I hope I have expressed my questions clearly.
Oh, another part I need to add to my script is -stim_times_subtract TR/2 , because I performed slice timing correction in fmriprep. Since my TR is 2 seconds, I should use -stim_times_subtract 1 .
Comparing Conditions without Covariates
If you’re comparing conditions without including the preference score as a covariate, use the -stim_times option rather than -stim_times_AM1.
Including Preference Score as a Covariate
When considering the preference score as a covariate, first ask whether the condition causally affects the preference score. If so, use the -stim_times_AM2 option. You could input mean-centered covariate values, as you demonstrated. On the other hand, 3dDeconvolve will automatically mean-center these values for you.
Intercept Effects and Mean-Centering
The estimated effects for the intercept (mean-centered covariate) from option (2) will not match exactly with those from (1) but should be very similar.
Assessing Effects Across Runs
If your goal is to evaluate effects across multiple runs rather than within individual runs, handle the covariate values consistently across runs and allow 3dDeconvolve to perform mean-centering. Note that the BOLD response estimate associated with the intercept (mean-centered covariate value of zero) reflects the BOLD response at the mean covariate level, not the baseline of the experiment.
Mediator Role of the Covariate
If the condition causally impacts the covariate (preference score), then the covariate serves as a mediator. If the main research interest is in the condition effect, it’s not essential to include the mediator as a covariate. However, if you do include it, mean-centering is critical. This distinction is covered in more detail here, which also explains why methods (1) and (2) yield similar results. Importantly, there is no rationale for orthogonalization in this context.
Explanation of TENTzero(0,16,9) Nodes and Intervals
With TENTzero(0,16,9), there are 9 nodes (or knots) across a 16-second window, resulting in 8 intervals. The first and last nodes are set to zero, so only 7 \beta coefficients are estimated.
Slice Timing Adjustment in fmriprep
I’m not familiar with the slice-timing adjustment specifics in fmriprep; if it adjusts timing to the midpoint of each TR, consider using -stim_times_subtract in 3dDeconvolve to account for this.
Thank you very much! I have modified my code. The code below does not include preference values, only the effects of conditions (single, scale, bundle) on activations.
when conducting group-level analysis later, how can I determine which two time points I want to compare? Specifically, how should I decide on the sub-brick values?
Additionally, after running my code, I obtained the following design matrix. In the image at the bottom, why do it seem that the last two time points for the last trial of the first condition extend beyond the image boundaries? Does this indicate there is an error?
For population-level analysis, it would be more informative to focus on all time points rather than extracting just one or a few. In other words, consider using all the estimated effects (i.e., sub-bricks labeled *#0_Coef, *#1_Coef, ..., *#6_Coef) to capture the full temporal profile. You can refer to this blog post for further insights.
Regarding your question about the last two time points in your design matrix, I can’t provide specific guidance without knowing the stimulus timing for the final trial. I suggest using 1dplot to visualize the last segment of the seven regressors for that particular condition. This can help you identify any irregularities or patterns that might raise concerns.
Gang Chen
The
National Institute of Mental Health (NIMH) is part of the National Institutes of
Health (NIH), a component of the U.S. Department of Health and Human
Services.