My question is about using "-stim_file" in 3dDeconvolve instead of "-stim_times" combined with BLOCK.
In my experimental design, the intensity of stimulus varies continuously throughout the duration, so the peak value of each impulse stimulus is not constant. Therefore, HRF for a single boxcar stimulus may not be particularly suitable.
So we chose to generate the HRF shape of the stimulus ourselves and made stim files for each stimulus condition for all runs (just like motion files, one value per TR). Then I did the 3dDeconvolve using the -stim_file option instead of the combination of -stim_times and BLOCK. The scripts are shown below.
We expect to get a better fit with -stim_file than with BLOCK, but in fact the F-stat of stats file is much smaller with -stim_file (F = 40.12) than with BLOCK(F = 280.41), I'm not sure why.
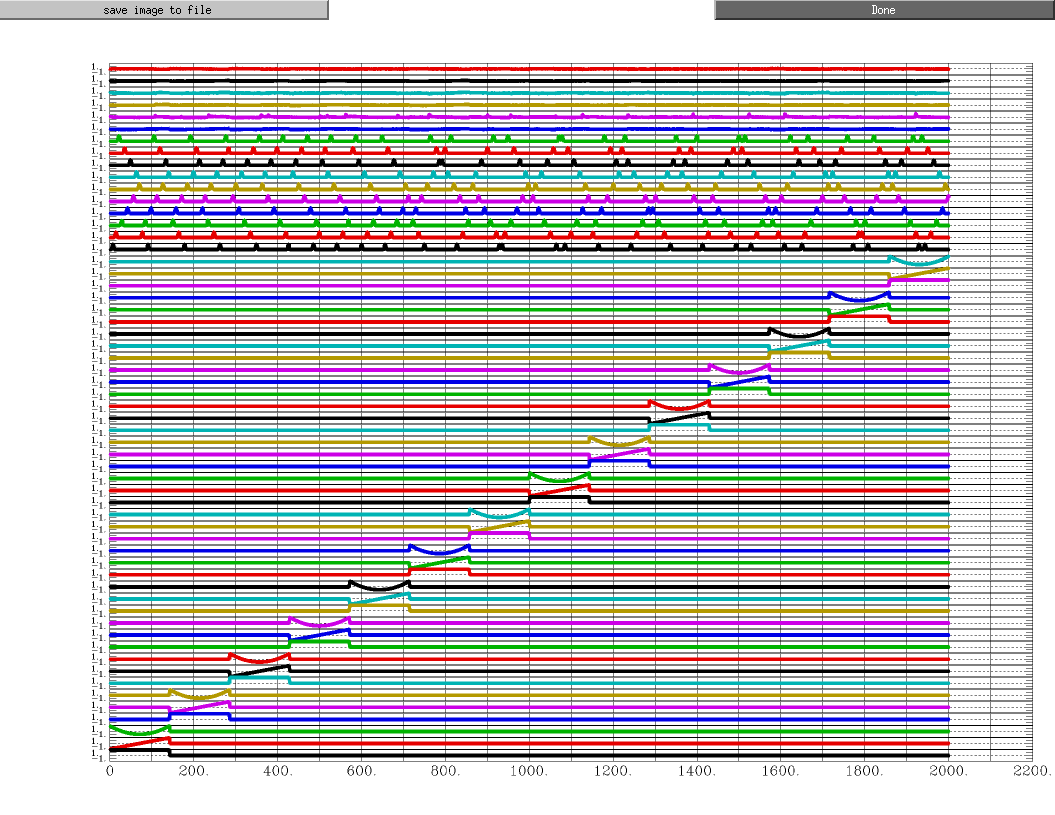
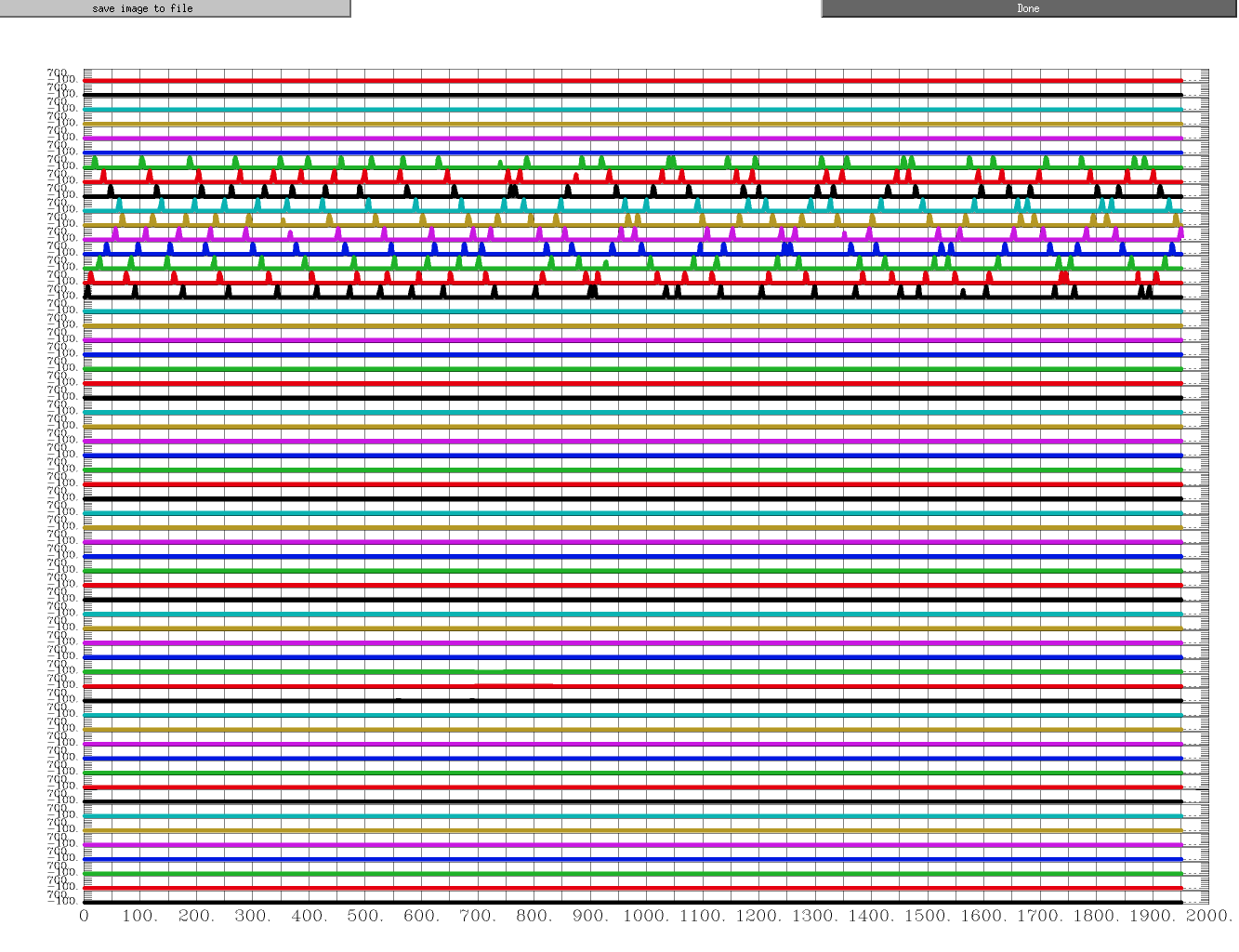
And I found that after using -stim_file if plot X.1D, regressor except for stimulus conditions (i.e. motion regressors and drifting regressors) became straight lines, and this is also where I am confused. The X.1D images using BLOCK and -stim_file are shown below respectively.
I have already used the TENT function that is not limited to the HRF shape and got some results, now we want to try using -stim_file to see if we can improve the fit further. The problems I encountered are as listed above. I'd be grateful if someone could help me!
Since I lack prior information about the customized HRF, I cannot assess its performance.
I have already used the TENT function that is not limited to the HRF shape and got some results
Did the TENT model render an improved fit quality compared to the BLOCK approach?
I found that after using -stim_file if plot X.1D, regressor except for stimulus conditions (i.e. motion regressors and drifting regressors) became straight lines, and this is also where I am confused.
If you haven't already, try adding the -sepscl option to your 1dplot command. This may help clarify the appearance of the plotted regressors.
Thank you for reminding me to use -sepscl option to 1dplot command. I realized that some regressors that looked like straight lines were actually not because the ordinate of the stimulus regressors was so large that it masked the former. It doesn't matter that the units of stimulus regressor are out of line with other regressors, does it? I tried to scale the stimulus stimfiles so that the stimfiles for all regressor were in the 0-1 range, but the 3dDeconvolve results showed no change and the F-value was still around 40, which was lower than 280 in the BLOCK results. So, maybe F=40 is the result of this analysis. I want to know if F=40 is necessarily worse than F=280, or if I need to look specifically at the activation statistics of each stimulus.
I don't know where we can say TENT is a better fit than BLOCK model. I thought they were just different forms to clarify the results. My understanding may not be deep enough. Do you have a better explanation? Now my main concern now is whether -stim_file can improve the result more than BLOCK method, and I think I need to try more.
It doesn't matter that the units of stimulus regressor are out of line with other regressors, does it?
The scale of a regressor affects the magnitude and interpretation of the associated regression coefficient, but it does not impact the corresponding statistical value or the overall model fit.
Now my main concern now is whether -stim_file can improve the result more than BLOCK method, and I think I need to try more.
In addition to the model fit metrics like the omnibus F-statistic and the coefficient of determination R^2, consider a more visually intuitive approach to comparing different models. Use the fitts option in 3dDeconvolve to obtain the fitted time series for BLOCK, TENT, and your customized HRF at each voxel. Load the output as UnderLay, click the Graph button, and compare one fitted time series with the input data and other fitted time series. You can see how to do this in this demo video at 3'20'' from the AFNI Academy.
The scale of a regressor affects the magnitude and interpretation of the associated regression coefficient, but it does not impact the corresponding statistical value or the overall model fit.
Thank you for explaining that! I checked them and you are right.
Load the output as UnderLay , click the Graph button, and compare one fitted time series with the input data and other fitted time series.
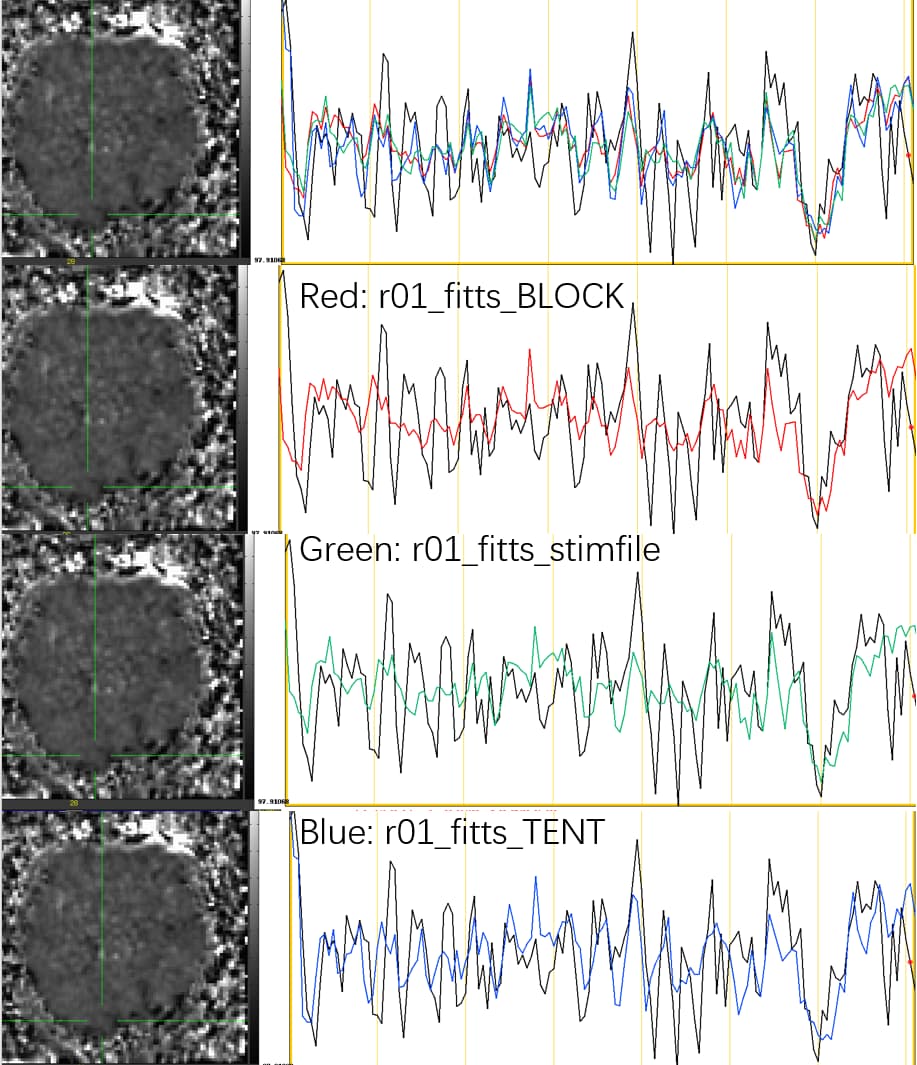
I used the fitts option for BLOCK, TENT and customized HRF, and for ease of loading, then I only extracted the run01 results of rall_fitts. Then I loaded pb05.subj.r01.scale+orig data as Underlay, and compared three kinds of r01_fitts time series on the Graph. I found that
the time series of underlay is not as smooth and regular as the demo video shows,
all of the three kinds of fitts time series don't seem to fit well to the pb05. r01 data. TENT seems to fit a little better than the other two methods.
Below is the graph for comparisons among r01_fitts time series, is it normal?
Is this a fast event-related experiment? Are you estimating hemodynamic responses at the trial or condition level? How many conditions and trials per condition are involved? How is the customized HRF chosen? Is the ultimate goal to make inferences at the individual or group level?
With 4 conditions, each having 10 repetitions of videos, there are a total of 40 videos. With 20 videos in each run, there should only be 2 runs of scanning. Why do you have 14 runs? What am I missing here?
Additionally, are the 4 repetitions under each condition the same video or different ones? If they are different, do the 4 repetitions have the same looming sequence (e.g., weights) under each condition? What is the TR? How many regions are you considering for the ROI analysis?
Let me see if I understand the experiment correctly. At the individual level, there are a total of 280 videos, decomposed into the following structure:
Differentiation of Identities: Do you differentiate the four different identities? In other words, are you trying to capture the BOLD response for each of those 10 [5 \, (\text{stimulus types}) \times 2 \, (\text{directions})] or each of those 40 [$5
(\text{stimulus types}) \times 2 , (\text{directions}) \times 4 , (\text{identities}$] videos?
Participants: How many participants do you have?
Modeling with BLOCK is likely too crude in this case. Regarding the issue of customized HRF versus hemodynamic response estimation through deconvolution (e.g., TENT), here are the pros and cons:
Customized HRF:
Pros: Theory-driven, providing the expected response. Very efficient with a single explanatory variable. Easier and more straightforward group-level analysis.
Cons: Any deviations from the hypothesized HRF can introduce biases.
Deconvolution (e.g., TENT):
Pros: Likely fits the data better, capturing subtle response shapes that might be missed by a customized HRF.
Cons: Less efficient, requiring many individual regressors. More complex group-level analysis.
I suggest trying both approaches and comparing their performance at both individual and group levels.
At the individual level, there are a total of 280 videos, decomposed into the following structure: 5 (stimulus types) x 2 (directions) x 4(identities) x 7(repetitions)
Yes, your understanding is correct.
1.Do you differentiate the four different identities?
No, I don't want to differentiate the four different identities. I'm not interested in the response difference between the four identities. We just want to capture the BOLD response for each of those 5 (stimulus types) x 2 (directions).
2.How many participants do you have?
We have 24 participants, but 2 of them may not be considered because of head motion or sleepiness. Now I use 22 participants' data to do analysis.
Thank you for your suggestion on Customized HRF and TENT. Pros and Cons you explain are really helpful!
I'm looking at the group analysis for Customized HRF right now, and it does provide different information than BLOCK on the activation map in some contrasts.
Thanks again for the time you spent on my question!
Shulei
The
National Institute of Mental Health (NIMH) is part of the National Institutes of
Health (NIH), a component of the U.S. Department of Health and Human
Services.