AFNI version info (21.1.20):
Dear all,
I am running data analyses on a task-based fMRI study and here is my issue.
I am using me-ica to preprocess the data, and apply the normalization to the generated data in their native space as follow:
I first warp my anatomical data to the MNI and then apply 3dWarpApply to the preprocessed data in their native space.
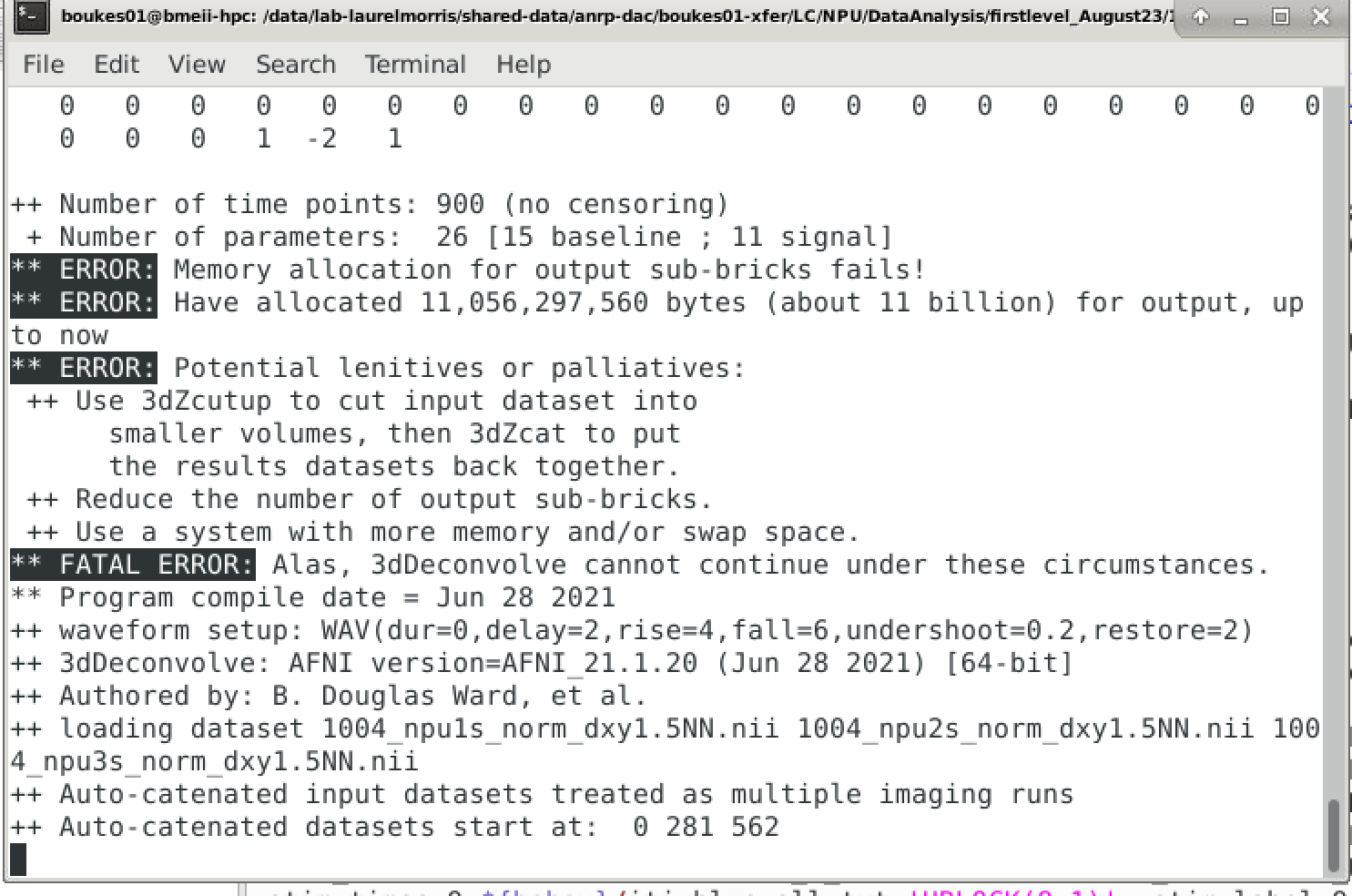
While the size of my native output is about 175.3 MB, after applying the normalization, the generated output is about 16.4 GB.
When I am applying the same normalization to a different set of resting state data, the issue does not occur and the output generated is of normal size (approximately 30 MB).
I don’t really understand why I obtain such a big file with my task-based fMRI data, and this prevents me from running the second level analyses (3dMVM) effectively as I took more than three days to be processed.
Any help would be greatly appreciated.
Thanks.
Here is the code used for normalization:
mni=/mypath
for i in subj_ID;
echo "-------------------------------"
echo "Working on subject: $i at: $(date +%Y-%m-%d-%H:%M:%S)"
echo "-------------------------------"
sleep 2 # Two seconds pause
curr_warp=$mni/${i}/anatQQ.sswarp_anat2mni_WARP.nii
curr_aff12_1D=$mni/{i}/anatQQ.sswarp_anat2mni.aff12.1D
cd /path Subj_ID
for j in 1 ; do
#3dNwarpApply -overwrite -nwarp "$curr_warp $curr_aff12_1D" -source ${I}_task${j}_T1c_medn_nat.nii.gz -ainterp NN -master $mni/template/mni+tlrc. -dxyz 1 -prefix ${i}_task${j}_T1c_medn_norm -verb
done
done