Can I ask what “-combine_method …” you are using? I guess it is either the older (Kundu et al) or newer (du Pre et al) MEICA? Probably it is going to be an issue within that software specifically to try to work out.
I pinged some MEICA experts here, and the advice was:
That particular error message could apparently come up relatively often in the older (Kundu et al.) MEICA, but the recommended way to solve/address/avoid it would be to use the newer tedana (Du Pre et al.): https://tedana.readthedocs.io/en/stable/
It integrates into your afni_proc.py command in essentially the exact same way as using the older version, just using a different “-combine_method METHOD”, such as m_tedana instead of tedana. Here is the AP help snippet about MEICA group tedana option usage:
---- combine methods that use tedana from the MEICA group ----
The MEICA group tedana is specified with 'm_tedana*' methods.
This tedana requires python 3.6+.
AFNI does not distribute this version of tedana, so it must
be in the PATH. For installation details, please see:
https://tedana.readthedocs.io/en/stable/installation.html
methods
m_tedana : tedana from MEICA group (dn_ts_OC.nii.gz)
m_tedana_OC : tedana OC from MEICA group (ts_OC.nii.gz)
m_tedana_m_tedort: tedana from MEICA group (dn_ts_OC.nii.gz)
"tedort" from MEICA group
(--tedort: "good" projected from "bad")
Hi, thank you for your reply.
I’m using the m_tedana, which works fine on all the other runs.
I have a specific run that keeps falling due to this issue.
Do you have any other thoughts on it?
Thank you,
Michal
What version of tedana are you using. AFNI should use whatever version of tedana is in your path so, if you type
tedana --version
that should tell you.
The most common reason this happens is if too many components are retained during the PCA dimensionality reduction step. As part of the tedana output, you should have a file called tedana_[date/time].tsv. There should be a section that looks like:
2022-11-22T15:17:19 pca.tedpca INFO Computing PCA of optimally combined multi-echo data with selection criteria: aic
2022-11-22T15:17:27 pca.tedpca INFO Optimal number of components based on different criteria:
2022-11-22T15:17:27 pca.tedpca INFO AIC: 71 | KIC: 62 | MDL: 42 | 90% varexp: 128 | 95% varexp: 162
2022-11-22T15:17:27 pca.tedpca INFO Explained variance based on different criteria:
2022-11-22T15:17:27 pca.tedpca INFO AIC: 0.802% | KIC: 0.784% | MDL: 0.735% | 90% varexp: 0.9% | 95% varexp: 0.95%
For this dataset, I am using the AIC selection criterion which gives me 71 components with an explained variance of 80.2%. (This specific dataset has 200 volumes total). What numbers are you seeing here? You can either cut & paste this section, or attach your output file here.
I have tedana v23.0.2 and this is the output I see in the tsv:
2025-02-02T11:22:11
pca.tedpca
INFO
Computing PCA of optimally combined multi-echo data with selection criteria: aic
2025-02-02T11:23:00
pca.tedpca
INFO
Optimal number of components based on different criteria:
2025-02-02T11:23:00
pca.tedpca
INFO
AIC: 215
2025-02-02T11:23:00
pca.tedpca
INFO
Explained variance based on different criteria:
2025-02-02T11:23:00
pca.tedpca
INFO
AIC: 0.999%
2025-02-02T11:23:00
pca.tedpca
INFO
Plotting maPCA optimization curves
2025-02-02T11:23:01
collect.generate_metrics
INFO
Calculating weight maps
2025-02-02T11:23:21
collect.generate_metrics
INFO
Calculating parameter estimate maps for optimally combined data
2025-02-02T11:23:38
collect.generate_metrics
INFO
Calculating z-statistic maps
2025-02-02T11:23:39
collect.generate_metrics
INFO
Calculating F-statistic maps
2025-02-02T11:24:51
collect.generate_metrics
INFO
Thresholding z-statistic maps
2025-02-02T11:25:10
collect.generate_metrics
INFO
Calculating T2* F-statistic maps
2025-02-02T11:25:30
collect.generate_metrics
INFO
Calculating S0 F-statistic maps
2025-02-02T11:25:51
collect.generate_metrics
INFO
Counting significant voxels in T2* F-statistic maps
2025-02-02T11:25:51
collect.generate_metrics
INFO
Counting significant voxels in S0 F-statistic maps
2025-02-02T11:25:51
collect.generate_metrics
INFO
Thresholding optimal combination beta maps to match T2* F-statistic maps
2025-02-02T11:26:52
collect.generate_metrics
INFO
Thresholding optimal combination beta maps to match S0 F-statistic maps
2025-02-02T11:27:41
collect.generate_metrics
INFO
Calculating kappa and rho
2025-02-02T11:27:42
collect.generate_metrics
INFO
Calculating variance explained
2025-02-02T11:27:42
collect.generate_metrics
INFO
Calculating normalized variance explained
2025-02-02T11:27:42
collect.generate_metrics
INFO
Calculating DSI between thresholded T2* F-statistic and optimal combination beta maps
2025-02-02T11:27:43
utils.dice
WARNING
179 of 215 components have empty maps, resulting in Dice values of 0. Please check your component table for dice columns with 0-values.
2025-02-02T11:27:43
collect.generate_metrics
INFO
Calculating DSI between thresholded S0 F-statistic and optimal combination beta maps
2025-02-02T11:27:43
utils.dice
WARNING
103 of 215 components have empty maps, resulting in Dice values of 0. Please check your component table for dice columns with 0-values.
2025-02-02T11:27:44
collect.generate_metrics
INFO
Calculating signal-noise t-statistics
2025-02-02T11:27:45
collect.generate_metrics
INFO
Counting significant noise voxels from z-statistic maps
2025-02-02T11:27:46
collect.generate_metrics
INFO
Calculating decision table score
2025-02-02T11:28:31
pca.tedpca
INFO
Selected 215 components with 99.91% normalized variance explained using aic dimensionality estimate
2025-02-02T11:54:09
ica.tedica
WARNING
ICA with random seed 42 failed to converge after 500 iterations
2025-02-02T11:54:09
ica.tedica
WARNING
Random seed updated to 43
After this, it gets stuck:
INFO pca:tedpca:396 Selected 215 components with 99.91% normalized variance explained using aic dimensionality estimate
/opt/homebrew/lib/python3.12/site-packages/tedana/io.py:345: FutureWarning: Downcasting behavior in `replace` is deprecated and will be removed in a future version. To retain the old behavior, explicitly call `result.infer_objects(copy=False)`. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
deblanked = data.replace("", np.nan)
WARNING ica:tedica:71 ICA with random seed 42 failed to converge after 500 iterations
WARNING ica:tedica:77 Random seed updated to 43
and keeps updating and never finishes. It also seems to be a problem for (at the moment) two participants of the same run.
I'd be happy for any feedback or tips on how to resolve it.
Thanks in advance!
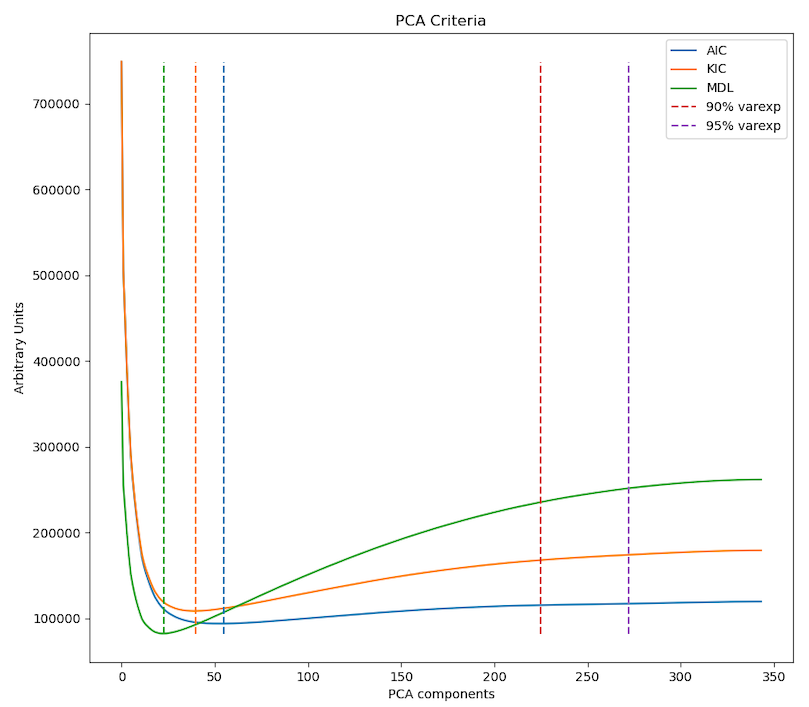
This is a known issue with the PCA component estimation step. It's supposed to look for a local minimum. If you look at ./figures/pca_criteria.png, you'll see the curves for AIC and the other criteria. Since you are showing variance=99.9% I suspect you'll see an AIC curve that keeps decreasing without a local minimum. For runs where the estimated number of components is more plausible will have plots with a more clear local minimum.
There are several ways to address this. First, check the other fit criteria (KIC and MDL) to see if they more reliably have a local minimum & consider using that instead of AIC. That said, when one fails, they all tend to have problems.
The other solution is that we've recently added robustica. This iteratively runs ICA to get more stable ICA outputs. In the process, it also reduces the total number of components to however many stable ones can be calculated. That means, if most of your good runs, have 80-90 components, you can run tedana with --ica_method robustica --tedpca 90. This will feed the ICA step 90 PCA components and ICA will will reduce this to a stable number of ICA components.
Thanks for your answer. I updated tedana and will try to run it with robustica. The link to the docs you sent is great, thanks! But it doesn't say how many components you should try. How did you get to 80-90? I see in the data around and over 200 but that seems a lot. How do I choose them?
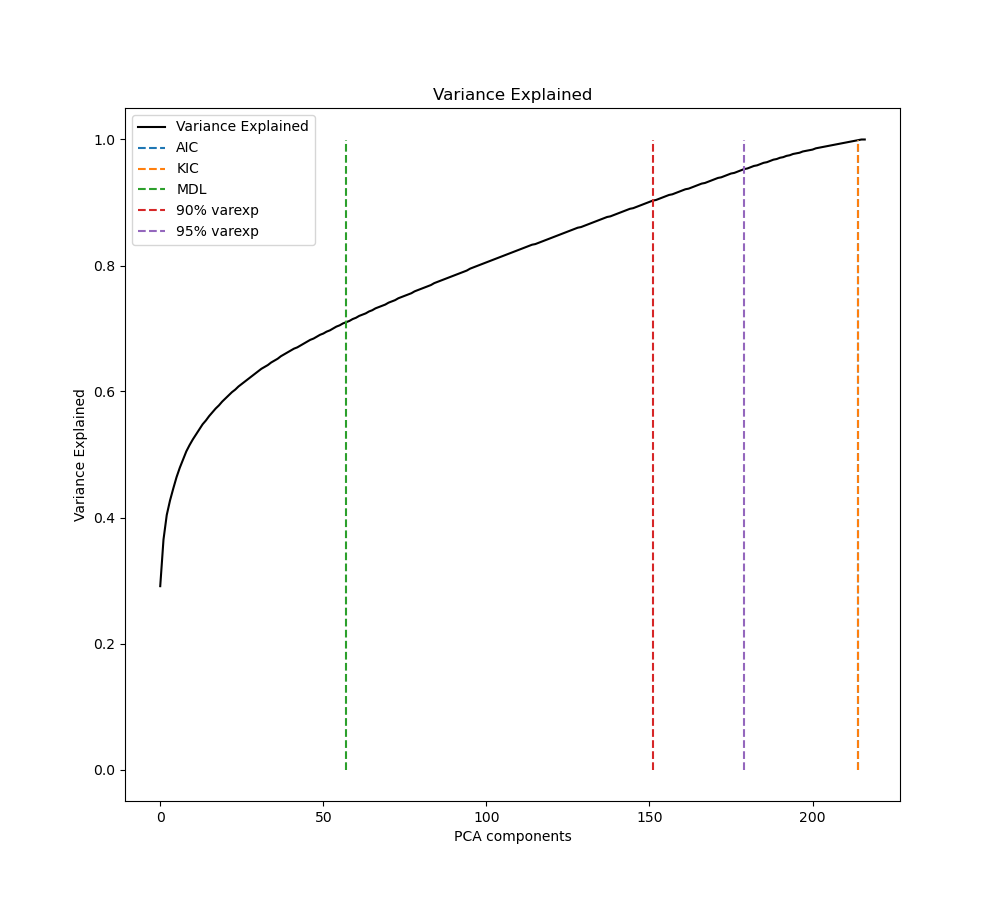
Regarding the explained variance saved in pca_criteria.png, it looks like this:
But it doesn't say how many components you should try. How did you get to 80-90?
This involves a bit of trial and error. If you run tedana on your data and get plausible estimates 4/5 of the time and it fails the rest, then pick something close to the highest plausible value from the good runs. There are three ways to define "plausible":
For typical fMRI where you're not doing something like pushing the limits of thermal noise with very small voxels, I'd expect the number of components to be 20-40% of the time of fMRI volumes (time points). That is, for a run with 200 volumes, I'd expect 40-80 components.
You can look at the curves from the PCA estimates. Note the file is ./figures/pca_criteria.png with the figures having the title "PCA Criteria" (There's another file ./figures/pca_variance_explained.png which is what you've pasted above. That shows how much variance is explained at each threshold.) I'm going to paste a few examples to show what the criteria should look like.
This one is reasonable. For the AIC, KIC, and MDL cost functions, the value drops, there's a clear local minimum, and then it gradually increases.
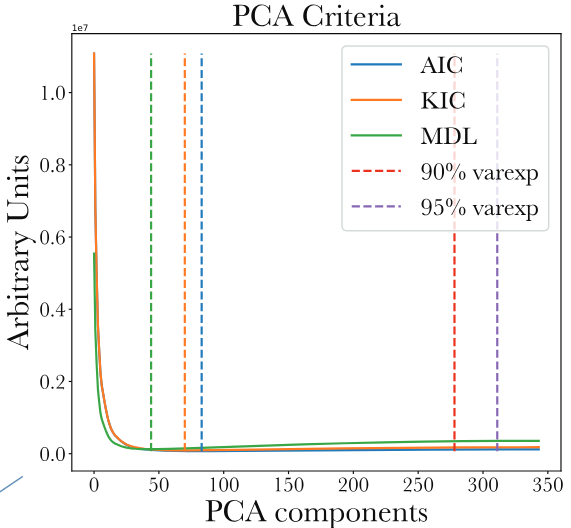
I can't quickly dig up a great example, but sometimes the curves have a similar initial drop and are flat for even decreasing without a clear local minimum. In these cases, the number selected as a local minimum is noiser and is sometimes the highest value (i.e. number of components = number of volumes). This is another failure state.
FWIW, my current hypothesis on the reasons for these values is that these cost functions assuming independent and identically distributed data and so some times to make fMRI data more i.i.d. but modern acceleration methods cause problems.
If you are running tedana with robustICA, look at the outputs of some runs & play around. Start with a high value, like 100 for 200 time points. By default, robustICA runs 30 iterations of ICA. If your initial pick is too high, you'll see a 5+ messages about ICA failing to converge on the screen and it keeps repeating until it gets 30 iterations of ICA that do converge. Then step down to try another starting point. robustICA also reduces the number of components. If you request 90 components and robustICA outputs 80-85 ICA components, that's a good sign. If you request 90 and get 70 ICA components, you should try a lower initial value. For this approach, I'd recommend running just tedana on some data you've already preprocessed with AFNI rather than repeated running afni_proc just for the tedana step.
One more (maybe silly) question, I use proc.py with -combine_method m_tedana \, where do the flags go?
In addition to including -combine_method m_tedana there's another flag: -combine_opts_tedana that is used to pass parameters to tedana. To run tedana with robustICA and starting with 90 components, you could include -combine_opts_tedana --tedpca 90 --ica_method robustica If you want to play with the number of ICA iterations that are used by robustICA, you can also include --n_robust_runs That might be useful if you want to quickly test a bunch of starting points with 10 iterations.
Best
Dan
The
National Institute of Mental Health (NIMH) is part of the National Institutes of
Health (NIH), a component of the U.S. Department of Health and Human
Services.