I'm trying to run permutation tests to cross-validate the individual results from an RSA analysis at the group level. The purpose is to get those clusters that are consistently found across subjects for a given contrast. I will try to specify.
Current state:
I ran a RSA searchlight analyses on the individual space, after minimal preprocessing, and using the betas from the GLM (with each trial as a condition in the GLM). So what I have is an individual map of Spearman's rho values that reflect the similarity between each center of sphere and a given empirical model. That for all the 30 subjects I have.
Purpose:
I know that some people would simply average those results in an MNI space, and set a (relatively) arbitrary threshold based on percentiles. That works but it does not account so well for potential inter-individual differences in the location of the similarities.
Hence, I thought of running a cross-subject permutation test to "validate" those clusters that are more likely to be found consistently across subjects. I thought that could be done with 3dttest++ (with -clustsim?), but I wasn't sure about the ideal parameters (and whether it makes sense).
Does this make sense at all, or am I completely off?
Thanks a lot, I'll happily provide more details if this is not clear enough!
If you convert the Spearman's \rho values into Fisher's z-values, you can then perform t-tests using 3dttest++. For reporting results, you may consider using the "highlight, but don't hide" approach, as discussed here.
There is something that is bugging me... I did as you said, and I intend to follow the highlight but don't hide approach. The Clustsim part seems fine, but the contrast image is giving me headaches. More details of what I did:
Transform to Fisher Z with the following (iterating over all images):
3dcalc -a ${i} -expr 'atanh(a)' -prefix $out_dir/FisherZ_${i}
Run 3dttest++ with -Clustsim:
3dttest++ -Clustsim -prefix ${res_dir}/semantic -mask ../MNI_mask+tlrc.HEAD -setA [paths to Fisher z images of the 30 subjects]
This outputs a bucket with brick0=mean stat and brick1= Z score. It is this Z score that I struggle to make sense of... It does not seem to correspond to the mean values at all. I would expect perhaps some differences with the mean but... I don't see where it comes from.
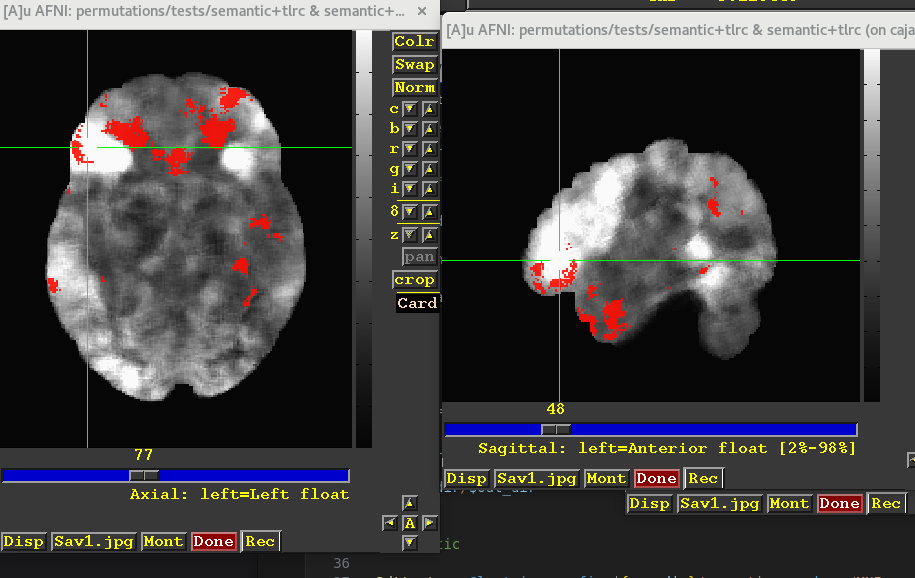
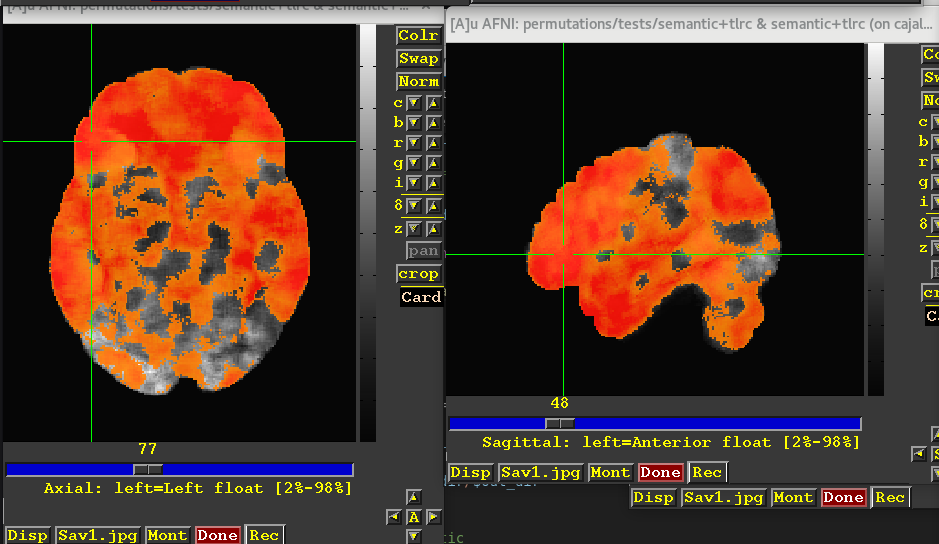
Underlay=mean brick; overlay = Zscore >5 (which is a riddiculously low p)
So filtering by p value using the Zscore brick as threshold is pretty much "pointless". Everything is above 0.001, which offers next to no information. I think I'm missing something, or I did something wrong.
Again, if I filter the mean image by 99th percentile as I was doing before, it does make sense to me (truly, the voxels where the searchlight yielded the highest similarities at the group level). Then I could use the clustsim thresholds on that to highlight the above-threshold clusters... but that is a bit more arbitrary, and the clustsim output relies on the p value, so...
First, I recommend converting the group-level effect estimate (the "mean" brick from the 3dttest++ output) from the Fisher-transformed space back to the original correlation. Then, in the AFNI GUI, use an appropriate anatomical template as Underlay, set the group-level correlation as Overlay, and choose the statistical value for Threshold.
The overwhelmingly strong statistical evidence in your case might stem from the RSA methodology, as neighboring voxels are often highly similar. The principle behind the "highlight, but don't hide" approach is simple: avoid arbitrary cutoffs and instead emphasize stronger evidence while preserving information continuity.
Given the overwhelming strength of the evidence in your case, you may want to increase the stringency of both voxel- and cluster-level thresholds. After that, you can enable the A button (for translucency) above the threshold bar and the B button (for cluster boundaries). In your result reporting, consider focusing on the brain regions surrounding the highlighted clusters.
This is very helpful. Yep, the approach would work, but there must be some sort of error I cannot figure out.
The RSA outputs considerably low correlations (which I think is typical, and expected from the type of analysis), and with quite low variability. I would have expected quite the opposite (very low power). Could the low variability be playing a role?
-- At sub-brick #0 'SetA_mean' datum type is float: -0.000844239 to 0.0227377
I will double-check the RSA methodology for sure, but I still don't quite understand how the distribution of the Zscore differs that much from the averaged correlations. There is of course some inter-individual variability and the Zscore needs not to reflect exactly the mean correlations. But what is very puzzling to me is how the average of the effects in the 30 subjects can be sooo different compared to the statistical contrast.
I shared that image using the mean as underlay in trying to convey this. It is the same contrast, but the "white blobs" (highest correlation values on average) don't match the highest Z scores (red blobs in the overlay) in the slightest.
It's common in neuroimaging papers to flaunt t, Z, or p values with color bars and tables, but rarely show the actual effect sizes. It’s like physicists discussing the speed of light but only reporting a p-value—great for maintaining a sense of mystery. The issue you're raising resonates with concerns we’ve been advocating for years, as highlighted in this paper and a recent blog post.
Although I'm not familiar with the specifics of RSA, the group-level average correlation values you mention, mostly in the range of [0, 0.02], are concerning. Such small values, coupled with likely low cross-individual variability, can easily result in superficially high statistical values. Without direct access to your data, it's hard for me to evaluate the situation fully. However, I recommend taking a closer look at the entire RSA process to ensure accuracy. Let me know if there's any further assistance I can provide.
Gang Chen
The
National Institute of Mental Health (NIMH) is part of the National Institutes of
Health (NIH), a component of the U.S. Department of Health and Human
Services.